En Juice Studio estamos viendo un patrón muy claro: cada vez más equipos quieren pasar de “probar prompts” a construir capacidades de IA que sean estables, medibles y gobernables. Ahí es donde el fine-tuning de LLM con LoRA se vuelve una palanca real de producto. No porque sea “la moda”, sino porque resuelve un problema muy concreto: conseguir que un modelo se comporte de forma consistente en un dominio, un estilo y unos formatos concretos, sin asumir el coste y la complejidad del entrenamiento completo.
Dicho de forma simple: cuando necesitas que la IA deje de ser un “asistente genérico” y empiece a actuar como una pieza fiable de tu stack, el fine-tuning de LLM con LoRA es, muchas veces, el camino más eficiente.

En este artículo vamos a cubrirlo con mentalidad de ingeniería y producto: qué técnicas existen, cómo decidir entre fine-tuning y RAG, cómo preparar datasets, qué hiperparámetros importan de verdad, cómo evaluar, y cómo llevar un sistema a producción sin que se te dispare el coste por token ni el riesgo de regresiones.
Qué es el fine-tuning y qué no es
El fine-tuning consiste en tomar un modelo preentrenado (un LLM “generalista”) y ajustarlo con datos específicos para que mejore su rendimiento en una tarea o un dominio. La clave es que el modelo ya sabe lenguaje, estructura y razonamiento general; el fine-tuning “dirige” ese conocimiento.
Lo que el fine-tuning sí hace bien:
- Adaptar estilo, tono y formato de respuesta
- Mejorar la precisión en tareas repetitivas y definidas
- Reducir variabilidad en outputs (más consistencia)
- Incluir conocimiento relativamente estable en el comportamiento
Lo que el fine-tuning no resuelve por sí solo:
- Tener información siempre actualizada (para eso, RAG o conexiones a fuentes vivas)
- Garantizar factualidad al 100 % sin grounding
- Sustituir una buena arquitectura de producto (observabilidad, fallback, evaluación)
Por eso, cuando planteamos un fine-tuning de LLM con LoRA, lo hacemos como parte de un sistema, no como una bala de plata.
Por qué el fine-tuning de LLM con LoRA es el punto de partida lógico
El entrenamiento completo (full fine-tuning) toca todos los parámetros del modelo. Funciona, pero es caro, lento y difícil de operar. En cambio, el fine-tuning de LLM con LoRA es una familia de métodos “parameter-efficient” (PEFT): ajustas solo una fracción pequeña de parámetros mediante adaptadores, manteniendo congelados los pesos base.
Ventajas prácticas del fine-tuning de LLM con LoRA:
- Menor coste de GPU y VRAM
- Entrenamientos más rápidos
- Menos riesgo operativo (versionado, rollback, experimentación)
- Posibilidad de tener “múltiples especializaciones” del mismo modelo base, cambiando adaptadores
Y esto tiene un impacto directo en producto: puedes iterar más rápido, testear hipótesis y ajustar el comportamiento con ciclos cortos.
Técnicas principales de fine-tuning que conviene conocer
Antes de entrar a LoRA, conviene ordenar el mapa general. En proyectos reales solemos ver cuatro grandes familias, y el fine-tuning de LLM con LoRA vive sobre todo en la capa de ajuste eficiente.
Supervised fine-tuning
Entrenas con pares de entrada y salida correctas (prompt → respuesta ideal). Es la base para instruction tuning y para especializar modelos en tareas específicas.
Cuándo encaja:
- Formatos de salida estrictos (JSON, plantillas, informes)
- Clasificación, extracción, normalización
- Soporte con guiones y tono definido
Instruction tuning
Es un tipo de supervised fine-tuning centrado en “seguir instrucciones” con ejemplos bien estructurados. Es especialmente útil cuando quieres que el modelo sea consistente en cómo responde a distintos tipos de petición, dentro de un dominio.
RLHF
Alineación con feedback humano: el modelo aprende preferencias (qué respuesta es mejor). Es potente, pero más complejo de operar.
Cuándo encaja:
- Productos con requisitos fuertes de “helpfulness vs safety”
- Necesidad de calibrar estilo y políticas finas
- Equipos con capacidad para operar pipelines más complejos
DPO
Una alternativa práctica a RLHF cuando tienes datos de preferencias (respuesta A vs respuesta B) y quieres un método más directo y estable. En muchos stacks modernos, DPO se ha convertido en el “siguiente paso” cuando el supervised se queda corto.
En la práctica, el fine-tuning de LLM con LoRA se combina con supervised y, si hace falta, con DPO para mejorar la alineación sin montar un circo de RL.
Qué es LoRA y por qué funciona
LoRA (Low-Rank Adaptation) parte de una idea útil: cuando adaptas un modelo a una tarea, los cambios efectivos en los pesos suelen tener “baja dimensionalidad”. En lugar de reentrenar todo, introduces matrices de baja dimensión en capas del transformer para aprender esas actualizaciones de forma compacta.
En términos operativos, el fine-tuning de LLM con LoRA:
- Congela el modelo base
- Entrena adaptadores pequeños (los “deltas”)
- Permite luego cargar el modelo base + adaptadores para inferencia
- En muchos escenarios permite incluso fusionar (“merge”) adaptadores si lo necesitas
La consecuencia: puedes tener un modelo base común y adaptadores por caso de uso, por idioma, por producto o por vertical.
QLoRA y la realidad del presupuesto
En el mundo real, el cuello de botella suele ser VRAM. QLoRA extiende LoRA combinándolo con cuantización, para poder entrenar adaptadores sobre modelos grandes sin que te explote la memoria.
Qué aporta QLoRA al fine-tuning de LLM con LoRA:
- Mantener el modelo base cuantizado (por ejemplo, 4-bit) durante entrenamiento
- Entrenar adaptadores LoRA encima
- Reducir VRAM necesaria sin matar el rendimiento
Si estás en un equipo que quiere resultados sin un cluster enorme, QLoRA suele ser el camino pragmático. Aun así, el criterio no debe ser “cuanto más barato mejor”, sino “qué caída de calidad es aceptable para este producto”.
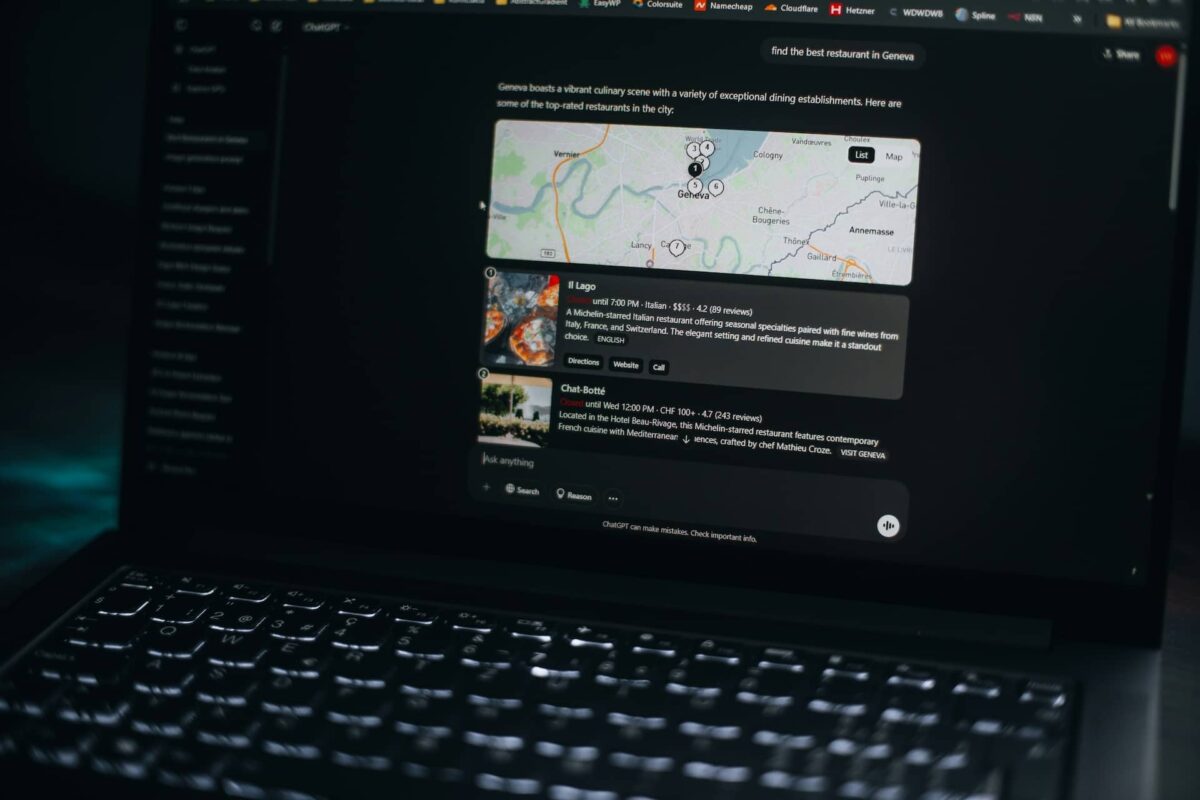
Fine-tuning vs RAG: cómo decidimos sin ideología
Una de las decisiones más importantes antes de empezar un fine-tuning de LLM con LoRA es si realmente necesitas fine-tuning o si RAG te cubre.
Elige fine-tuning cuando
- Necesitas consistencia de estilo y formato
- El conocimiento es relativamente estable
- Quieres reducir variabilidad y “sorpresas” en outputs
- El modelo debe aprender patrones de tu negocio (clasificaciones internas, taxonomías, plantillas)
Aquí el fine-tuning de LLM con LoRA suele dar el mayor ROI.
Elige RAG cuando
- Tu información cambia mucho
- Necesitas trazabilidad y verificación (source attribution)
- Ya tienes un repositorio documental potente
- No quieres entrenar por falta de datos o tiempo
El híbrido suele ser lo más realista
En muchos productos, el modelo aprende “cómo hablar y operar” con fine-tuning de LLM con LoRA, y luego RAG le da “qué decir” con datos actualizados. Esto reduce alucinaciones y evita reentrenar por cada cambio de políticas, precios o catálogo.
Preparación de dataset: donde se gana o se pierde el proyecto
En Juice Studio insistimos mucho en esto: la calidad del dataset manda. Un fine-tuning de LLM con LoRA con datos mediocres suele dar un modelo mediocre, solo que ahora lo has “especializado” en mediocridad.
Formatos de datos típicos
Para supervised / instruction tuning:
instruccióninput(opcional)output(respuesta ideal)
Para preferencias (DPO):
promptchosen(respuesta preferida)rejected(respuesta no preferida)
Reglas prácticas de calidad
- Ejemplos cortos, claros y representativos
- Consistencia en el formato de salida
- Cobertura de casos límite (edge cases)
- Eliminación de duplicados y contradicciones
- Separación de train/validation/test sin “data leakage”
Si tu objetivo es un fine-tuning de LLM con LoRA que aguante en producción, no te obsesiones con volumen. Obsesiónate con consistencia.
Privacidad y compliance
Si hay PII o datos sensibles:
- Anonimiza antes de entrenar
- Documenta qué campos se transforman
- Define retention y acceso
- Alinea con legal y seguridad desde el día uno
No hay nada peor que un fine-tuning de LLM con LoRA “perfecto” que no puedes desplegar por compliance.
Paso a paso: cómo hacemos un fine-tuning de LLM con LoRA de forma seria
Aquí va un flujo operativo que funciona muy bien para equipos de producto e ingeniería.
1) Define el objetivo en términos medibles
Ejemplos:
- Aumentar accuracy en clasificación del 82 % al 92 %
- Reducir errores de formato JSON del 15 % al 2 %
- Mejorar “first response resolution” del agente en un KPI concreto
Sin KPI, un fine-tuning de LLM con LoRA se convierte en “me gusta más cómo suena”.
2) Crea un set de evaluación antes de entrenar
- Golden set con casos representativos
- Casos críticos (los que no pueden fallar)
- Regresión: errores históricos convertidos en tests
Esto es lo que evita que tu fine-tuning de LLM con LoRA mejore una cosa y rompa otra.
3) Elige un modelo base razonable
No siempre necesitas el modelo más grande. Para muchos casos, un 7B/8B bien ajustado rinde mejor en coste/latency que un 70B sin ajustar.
4) Empieza con LoRA antes de complicarte
Como heurística: primero fine-tuning de LLM con LoRA con supervised. Si no llega, añade DPO. Y solo si hace falta, exploras opciones más pesadas.
5) Ajusta hiperparámetros con criterio
Los que más importan:
- Learning rate (si te pasas, el modelo se “descoloca”)
- Rank de LoRA (capacidad del adaptador)
- Número de epochs (riesgo de overfitting)
- Batch size efectivo (gradient accumulation si hace falta)
- Early stopping basado en validación
Aquí un consejo claro: en fine-tuning de LLM con LoRA, más epochs no significa mejor. A menudo significa peor.
6) Evalúa, compara y decide con gates
Antes de “promocionar” a producción:
- Eval cuantitativa (tasa de acierto, formato, robustez)
- Eval cualitativa (revisión humana en casos clave)
- Eval de coste (tokens, latency, throughput)
Un fine-tuning de LLM con LoRA no se aprueba solo por calidad textual.
Evaluación: el componente que más se subestima
Si estás construyendo agentes o automatizaciones, el comportamiento deriva. Por eso, cada fine-tuning de LLM con LoRA necesita evaluación como sistema, no como check final.
Una pila que funciona:
- Evals deterministas (formato, tool calling, constraints)
- LLM-as-judge con rubric (utilidad, claridad, riesgo)
- Canary en producción (un % del tráfico) con rollback rápido
La regla operativa: cada fallo importante se convierte en un caso del golden set. Así el fine-tuning de LLM con LoRA mejora con el tiempo y no se vuelve frágil.
Casos de uso donde el fine-tuning de LLM con LoRA aporta más valor
Atención al cliente y soporte interno
- Tono consistente
- Respuestas con estructura estándar
- Clasificación de tickets
- Resumen y next steps
Aquí el fine-tuning de LLM con LoRA reduce variabilidad y mejora tiempos.
Automatización de operaciones y back office
- Extracción de campos de documentos
- Normalización de datos
- Generación de emails internos con formato fijo
- Workflows con tool calling (si está bien evaluado)
Legal y compliance (con cuidado)
- Redacción con plantillas
- Análisis y clasificación
- Resúmenes estructurados
Suele funcionar mejor con híbrido: fine-tuning de LLM con LoRA para el formato y RAG para datos actuales.
Code generation orientada a tu stack
- Estilo de código
- Patterns internos
- Documentación técnica con estructura
- Snippets para librerías específicas
Riesgos típicos y cómo mitigarlos
Overfitting
Se nota cuando el modelo “memoriza” ejemplos y pierde generalización. Mitigación:
- Menos epochs
- Mejor validación
- Dataset más diverso
Catastrophic forgetting
El modelo se especializa tanto que empeora en capacidades generales. Mitigación:
- Mezcla de datos (no entrenar solo en un microdominio)
- Evaluación de regresión
- Adaptadores por tarea (ventaja del fine-tuning de LLM con LoRA)
Alignment tax
A veces, al alinear estilo y seguridad, pierdes rendimiento en ciertas tareas. Mitigación: separar rutas, usar políticas, y medir trade-offs.
Producción: versionado, despliegue y mantenimiento
Un fine-tuning de LLM con LoRA en producción exige disciplina:
- Versionado de adaptadores (v1, v1.1, v2) con changelog
- Experimentos A/B o canary
- Observabilidad: tokens, latency, errores, tasa de fallback
- Rollback rápido si la calidad cae
- Monitorización de drift (cambios en entradas, cambios en datos, cambios de comportamiento)
Y un consejo pragmático: evita “reentrenar por impulso”. Primero identifica el fallo, conviértelo en caso de evaluación, y luego decides si lo arreglas con datos, prompt, RAG o un nuevo fine-tuning de LLM con LoRA.
Checklist final
Si vas a ejecutar un fine-tuning de LLM con LoRA, asegúrate de cumplir esto:
- Objetivo definido como KPI
- Golden set creado antes de entrenar
- Dataset limpio, consistente y sin contradicciones
- Primer ciclo con LoRA (sin complicar)
- Evaluación por regresión y rubrics
- Canary en producción con rollback
- Observabilidad de coste y latency
- Roadmap de mantenimiento (no solo “lanzar y ya”)
Roadmap
Primera etapa
- Definir KPI y casos de uso
- Instrumentar trazas y eventos
- Preparar dataset v1 y golden set v1
- Primer fine-tuning de LLM con LoRA con supervised
Segunda etapa
- Iterar dataset con errores reales
- Ajustar hiperparámetros
- Añadir DPO si hace falta
- Montar canary y gates de release
Tercera etapa
- Escalar el set de evaluación
- Operar releases con disciplina (versionado y rollback)
- Optimizar coste (modelo base, cuantización, caching)
- Consolidar el sistema híbrido si necesitas datos frescos
Cierre
El fine-tuning de LLM con LoRA es una herramienta extremadamente útil cuando se usa con mentalidad de producto: objetivos medibles, datos de calidad, evaluación continua y operación responsable en producción. Si lo planteamos así, deja de ser un experimento de laboratorio y se convierte en una capacidad estratégica: modelos que hablan tu lenguaje, siguen tus formatos y se integran en workflows reales con fiabilidad.
Y, por si quieres validar que cumplimos lo importante: a lo largo del artículo hemos trabajado el fine-tuning de LLM con LoRA como núcleo, pero sin convertirlo en repetición artificial. Lo hemos conectado a decisiones reales (RAG vs fine-tuning), a dataset y a evaluación, que es donde se decide el éxito o el fracaso en producción.

